Guaranteed qualified meetings with the local owners other agencies can’t reach
Most cold email agencies pull the same ZoomInfo and Apollo lists everyone else emails. We build verified lists of the business owners and decision-makers those tools miss, then write and send the campaigns that put meetings on your calendar. Completely done-for-you, and live as soon as tomorrow.
Book a call and we’ll show you a free sample of owners in your market that Apollo and ZoomInfo can’t, no commitment.
Free sample list on the callKeep every contact we buildNo long-term contract
This is what to expect
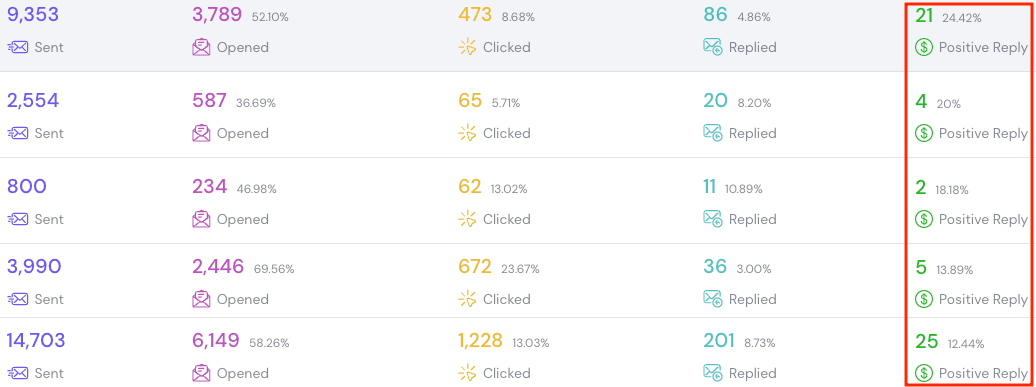
Results we’ve delivered
Companies that replaced manual list-building and outbound with our engine.
It’s not your copy. It’s your list.
If you sell to local owners (trades, home services, clinics, restaurants, auto), you’ve felt it: cold email fails before the first send, because every agency buys the same contacts and emails the same overworked inboxes. We compete on the one thing that actually moves reply rates: reaching people other tools can’t find.
Typical cold email agency
- Pulls the same ZoomInfo & Apollo lists every other agency emails
- Reaches gatekeepers and generic info@ inboxes, not owners
- Sends the 10th identical template that owner got this week
- Reply rates crater, and so does your pipeline
The Relevint difference
- Finds owners & decision-makers off-database: Maps, licenses, permits, socials
- Reaches the person who actually signs the check
- Lands in uncrowded inboxes that rarely get cold email
- Reply rates that actually fill your calendar
The list is yours forever.
Most agencies rent you meetings off data they rent too. The day you leave, you leave with nothing. We’re the opposite. The verified owner-level database we build for your market is yours to keep, whether you renew or not.
You’re not renting meetings. You’re walking away owning the one asset your competitors can’t get.
How it works
A complete outbound engine, built, run, and optimized for you. You take the meetings.
We build owner-level lists other tools can’t
We don’t pull the same ZoomInfo and Apollo lists everyone else is emailing. We research local businesses across Maps, license and permit records, directories, and social to find the actual owner and their real email, even when they’re nowhere in the standard databases.
You reach the owners your competitors can’t even find.
We write relevant messaging that earns replies
Every email is written from research on that specific business: what they do, where they operate, the pain they’re likely feeling, and why now makes sense. No merge fields. No “personalization theater.”
Messaging that makes a busy owner feel understood, because they are.
We send into uncrowded inboxes, without burning deliverability
These owners get a fraction of the cold email a corporate buyer gets, so your message actually gets seen. We protect that edge with thousands of warmed, auto-rotating inboxes, deliverability monitoring across every domain, and automatic reply handling and booking.
Less competition in the inbox + genuinely relevant messaging = meetings, daily.
Everything’s included
One done-for-you system: the data, the copy, the infrastructure, and the management.
Owner-level list building
We find local business owners across Maps, license & permit records, directories, and social, not just ZoomInfo & Apollo.
Verified owner emails
Real, deliverable inboxes for the decision-maker, not a generic info@ address or a gatekeeper.
Research-based copy
Every email written from research on that specific business. No merge fields, no “personalization theater.”
Deliverability infrastructure
Thousands of warmed, auto-rotating inboxes on separate domains, monitored so your brand stays protected.
Live as soon as tomorrow
You plug into pre-warmed domains and accounts, so we skip the weeks of warmup and ramp. Campaigns launch next day and first meetings land within days.
Full transparency
Reply handling, meeting booking, and weekly reporting + optimization handled for you. You take the meetings.
Meetings in days, not months
You plug into a proven system that’s already built and warmed, so there’s no waiting weeks for setup and ramp. Here’s how fast it moves.
Day 1
Plug in & launch
You plug into a system that’s already built: leads found, domains and accounts pre-warmed, infrastructure proven. Campaigns can go live as soon as the next day.
Days 2–5
Meetings start landing
Because we skip the weeks of warmup and ramp, replies come in and meetings start hitting your calendar within the first few days of sending.
Week 2
Steady daily flow
Campaigns hit full stride and settle into a consistent daily stream of qualified meetings.
Ongoing
Scale & optimize
We expand volume into new segments and optimize weekly off real reply and booking data.
Real campaigns. Real replies.
When you reach owners no one else is emailing, the numbers look different:
The ROI is obvious
Every meeting we book is pipeline you didn’t have to chase. Compare that to the alternative.
| Hiring an SDR | Relevint | |
|---|---|---|
| Time to first meeting | 3–6 months | 2–5 days |
| Year 1 cost | $140K+ all-in | A fraction of one hire |
| Who they reach | Same lists everyone buys | Owners others can’t find |
| Ramp & turnover risk | High (14-mo avg tenure) | None |
| Output | Unpredictable | Consistent daily meetings |
Bottom line: meetings start landing in days, not quarters, with owners your competitors can’t even reach. The system pays for itself in pipeline.
Is this right for you?
This is for you if:
- You sell to local business owners like trades, home services, clinics, restaurants, auto, or franchises
- Your best leads are hard to find in ZoomInfo, Apollo, or Clay
- You’ve found product-market fit and know who you sell to
- Outbound is happening, but list-building is the bottleneck
- You want leverage, not more headcount
This is NOT for you if:
- You sell to large enterprises with clean, widely-available data
- You’re pre-PMF or just “testing cold email”
- You’re optimizing for raw send volume
- You’re looking to spray & pray spam prospects
Frequently asked questions
How fast can you launch?
Fast. You’re plugging into a system that’s already built: leads found, domains and accounts pre-warmed, infrastructure proven. Campaigns can launch as soon as the next day, and because we skip the usual weeks of warmup and ramp, meetings start landing within the first few days of sending, not weeks later.
Don’t cold email domains need weeks of warmup first?
Normally yes, and that’s where most campaigns burn their first month. We maintain a standing pool of pre-warmed domains and rotating accounts, so the warmup is already done before you arrive. You plug into proven, healthy infrastructure and start sending right away, all without touching your primary domain.
How do you find owners ZoomInfo and Apollo can’t?
We don’t rely on a single database. We research local businesses across Google Maps, state and local license and permit records, industry directories, and social profiles to find the actual owner or decision-maker and verify their real email, even when they’re nowhere in the standard tools.
Will this hurt my domain reputation?
No. We never send from your primary domain. We run thousands of warmed, auto-rotating inboxes on separate domains, with deliverability monitored across every domain, so your main domain and brand stay protected.
What do I actually have to do?
Take the meetings. We handle list building, copy, sending infrastructure, reply handling, and booking. Qualified meetings land on your calendar and you get weekly reporting on performance.
What does it cost?
We run an 8-week pilot where we guarantee results and make sure you see a positive ROI. The pilot is a one-time fee, with no long-term commitment, and it’s a fraction of the all-in cost of a single SDR hire. We’ll walk through exact numbers on the call once we understand your ICP.
Who is this best for?
Companies that sell to local business owners (trades, home services, clinics, restaurants, auto, franchises) who’ve found product-market fit and whose best leads are hard to find in ZoomInfo, Apollo, or Clay.
See the owners everyone else is missing, before you spend a dollar.
On this call, we’ll:
- Hand you a free sample of verified owners in your market, the real decision-makers Apollo and ZoomInfo don’t have
- Show you exactly how we find and verify owners off-database
- Walk through the economics vs. buying lists and hiring SDRs
- Map out what a done-for-you system looks like for your specific market
You’ll leave the call with a sample list of real owners you can email today, whether we work together or not.